对volatile变量规则的独家理解
《Java并发编程的艺术》在第三章介绍了 JMM(Java 内存模型),在第 3.7.3 小节里提到了 6 条规则,即大名鼎鼎的 happens-before 规则。其中我认为入门玩家比较难理解的是第三条 —— volatile 变量规则。
volatile 变量规则
对于一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读。
咋一看好像说了很多,又好像什么都没说。中文社区内的解读大多是搬一些公式化的句子和一些模板化的代码,再深度解读一番 Store Load Barrier ,让你感觉他说得没错,但是不知道和这句话有什么关系,就如同没有这句话,程序那样运行依旧是天经地义的。
我甚至有点怀疑是不是因为翻译的原因导致这句话如此简单却难以理解。为此我特地找了一下原文,有兴趣的可直接看:
http://www.cs.umd.edu/~pugh/java/memoryModel/CommunityReview.pdf
原文在第三小节,如图 1:

原文就是这么直白而难懂。
渐近式理解
从一个刚接触 JMM 的萌新的角度来看,也许会产生以下想法,一一解读:
-
根据规则,“写先于读”,那是不是 volatile 变量不写就不能读呢?
- 否。这个“不写”的前提是不存在的,哪怕是不主动赋值,JVM 也会在初始化时为其赋个默认值。
-
单线程下,先改写 volatile 的值,再读,毫无疑问能读到改后的值。
- 是。顺序原则。
-
多线程下呢?如果是根据“写先于读”的话,读会等待写吗?也就是说如果发现同时有多个线程,其中在修改一个 volatile 值,其它都是读的线程,是不是读线程会阻塞,等写线程完成后才去读?
- 否。写个简单的测试如下,输出为 0,可知线程 t2 没有等 t1 改值就已经读到 x 了。
public class VolatileTest { public static void main(String[] args) { Critical critical = new Critical(); Thread t1 = new Thread(critical::read); Thread t2 = new Thread(critical::write); t1.start(); t2.start(); } } class Critical { private volatile int x = 0; @SneakyThrows public void write() { Thread.sleep(500); x = 1; } @SneakyThrows public void read() { Thread.sleep(300); System.out.println(x); } } -
为什么规则和上述实验现象不符合呢?
- 可能性有三点:一,规则错了;二,对规则的理解错了;三,实验有误差或设计不严谨。想想也知道,第二点可能性最大。
-
如果是对规则的理解不对导致实验思路就不对,那么如何理解?
-
首先要搞清楚理解偏差在哪个地方。问题的核心是 volatile 域,原文 volatile field,到底是个什么东西。它是我们在代码里声明的那个变量吗?这里又有个理解上的问题了:“代码里的变量”是什么?稍加思索你会发现,这个“代码中的变量”在计算机里可不仅仅是一个变量!它会在内存里有一个变量,在 CPU 的缓存里有三个或者其它数量(大部分 CPU 有三级缓存,也有部分 CPU 是非三级缓存的),而且说不定这时候 CPU 正在使用这个变量,那么此时在寄存器里也有此变量。这几个变量都是由同一句代码声明而产生的变量,那么描述它们还能用“代码中的变量”这样不准确的说法吗?显然不行了。
-
精确到目标的问题应该是: volatile 域是指内存里的那个变量,还是缓存里的那些个变量,亦或是其它? 这就需要结合语境了,volatile 规则是在 JMM 模型的大框架下建立的。JMM 模型是啥?就是用来描述在 JVM 中物理内存如何与 CPU 缓存通信,且内存中的数据如何参与 CPU 调度的模型。主角是内存,所以 volatile 域指的就是内存中的 volatile 变量。因为程序的底层调度并不像纸面代码那么简单直白,上面的实验就是如此,底层的逻辑粒度已经超过了代码能表述的粒度,所以我们只能用理论来描述代码的结果,而很难用代码来描述执行的过程。所以想仅仅站在代码的角度去理解 volatile 规则是不行的。
-
要理解 volatile 变量规则,要直接从 JMM 模型入手。如图2(图2来自知乎 @阿里云云栖号,侵删。)
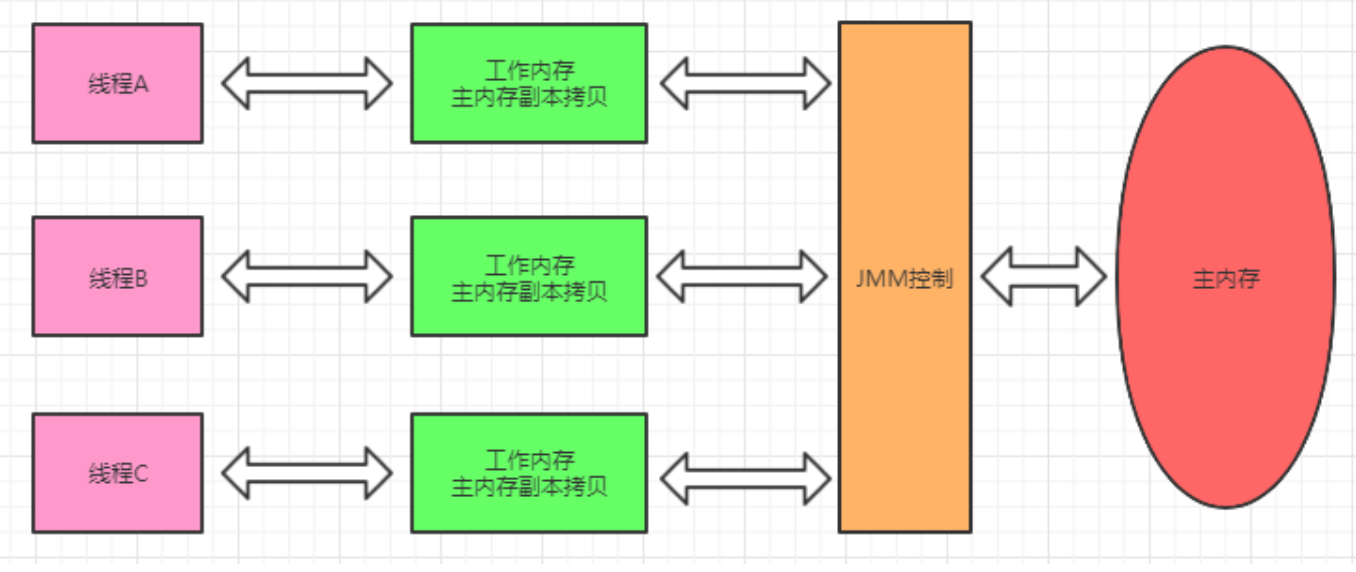
JMM 将底层复杂的物理硬件抽象成了简单的几层:主内存(大致对应物理上的内存条),JMM控制(大致对应存储层面的数据调度策略,由 JVM 封装好的逻辑),工作内存(各级缓存和寄存器),线程(CPU 在时钟周期内的运行动作)。
volatile 变量在主内存中。我们知道单线程的规则是顺序规则,而多线程在使用了主内存中的 volatile 变量时,volatile 规则就体现了。先将这个模型的结构图刻进脑海中,再来看一个经典的例子,应该比较好理解:
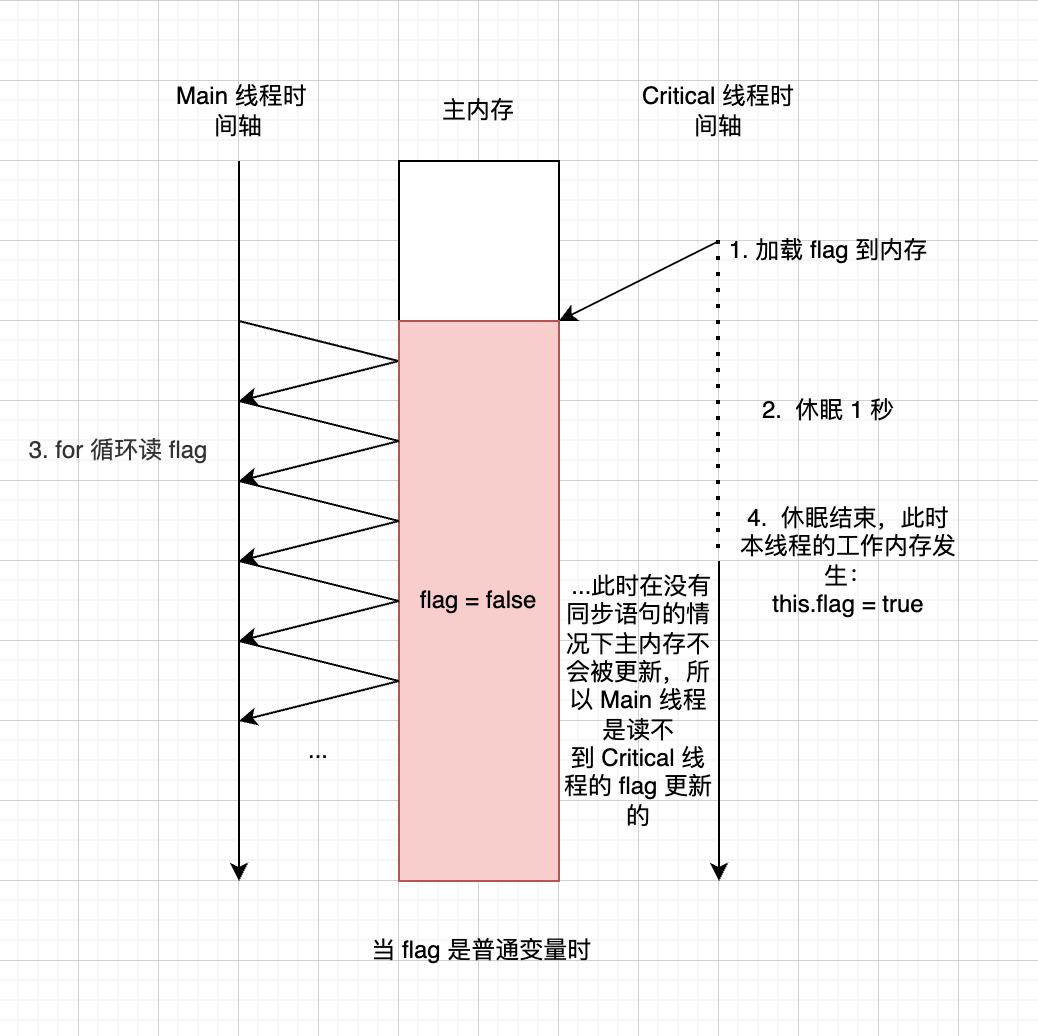
class Critical extends Thread { private boolean flag = false; // getter and setter @Override public void run() { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } this.flag = true; } } public static void main(String[] args) throws InterruptedException { Critical critical = new Critical(); critical.start(); for (;;) { if (critical.isFlag()) { System.out.println("Flag is set to true"); } } }main 方法执行后,你将永远也不会看到 “Flag is set to true” 的输出(因为没有同步语句执行,所以缓存内的值暂时不会写回内存),如图3:
如果将 flag 改为 volatile 类型的变量会怎样呢?那就肯定会输出 “Flag is set to true” ,如图4:
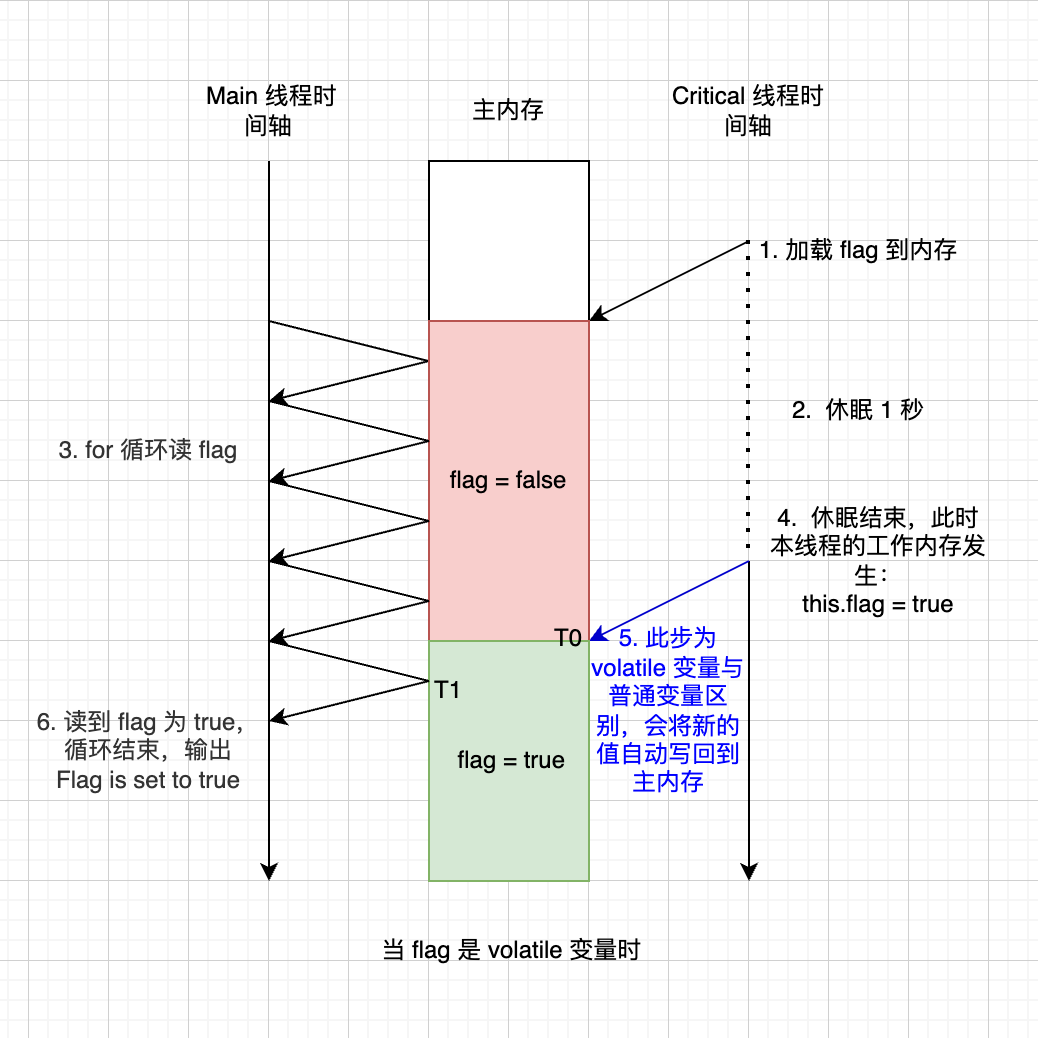
再来对 volatile 规则加以理解:对于一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读。
现在最大的问题是很容易觉得这个“写”存在歧义:一是我们的代码逻辑将线程工作内存设成 this.flag = true;二是主内存中的 flag = true。哪个才是规则里指的“写”操作呢?有了上述分析我们知道 “volatile 域” 就是主内存中的变量,于是毫无疑问这个“写”指的就是后者了。如上图,将写的时间点记为 T0。volatile 变量规则就可以翻译为 “T0 以后的读操作都在 T0 以后进行,比如 T1 在 T0 以后进行”。
???
好家伙,在这原地 TP 呢!听君一席话如听一席话是吧!我上次听到这么牛逼的话还是在上次!
搞了半天这个规则只想告诉我们一句牛逼的废话吗?**就如同没有这句话,程序那样运行依旧是天经地义的。**肯定还有哪里不对!
-
结论修正。回过头再想, volatile field 这个词是否还有其它含义?显然是有的,在 Java 的世界观中,本地变量就叫 field,那么其实线程的工作内存里的变量叫 volatile field 好像也没问题。这样的话,将图 3 与图 4 的第 4 步都认为是“写”操作,区别就出来了:普通变量的写操作对主内存后续的读操作无影响,而 volatile 变量的写操作对后续主内存的读操作有影响!
归纳一下,便得到一个结论:不考虑同步的前提下,普通变量的写操作对主内存后续的读操作无影响,而 volatile 变量的写操作对后续主内存的读操作有影响。详细的影响是:记 volatile 变量的写操作真正生效时间为 T0,那么 T0 时间点后的其它对主内存的读操作读到的肯定是写后的值。
我想这才是 volatile 变量规则想说的真正意思。
对规则咬文嚼字一下,得到图 5:

其实一般不需要像个强迫症一样每个字都抠出含义的,感觉能理解到上面的结论就差不多了。这点搞清楚然后再去讨论 volatile 变量规则是如何确保的,这才引出了 volatile 关键字的底层实现原理——内存栅栏(或者叫内存屏障)。不过这部分内容并不是什么很难理解的东西,就不在这里讨论了,翻翻书就明白了。
-
扩展式理解
至今看到不少文章都能将原理侃得很深了,但是缺少了现实的承载,显得抽象感极强,什么 CPU,缓存,主内存,令人云里雾里。在此我就把理论中经常提到的东西列出来,好让大家明白我们平时经常说的一些东西究竟是什么。
以我用的 AMD 5000 系列的 CPU 为例。上结构如下图。
日常使用的CPU(听说最近新的 DDR5 内存的 MC 移到了内存条上):
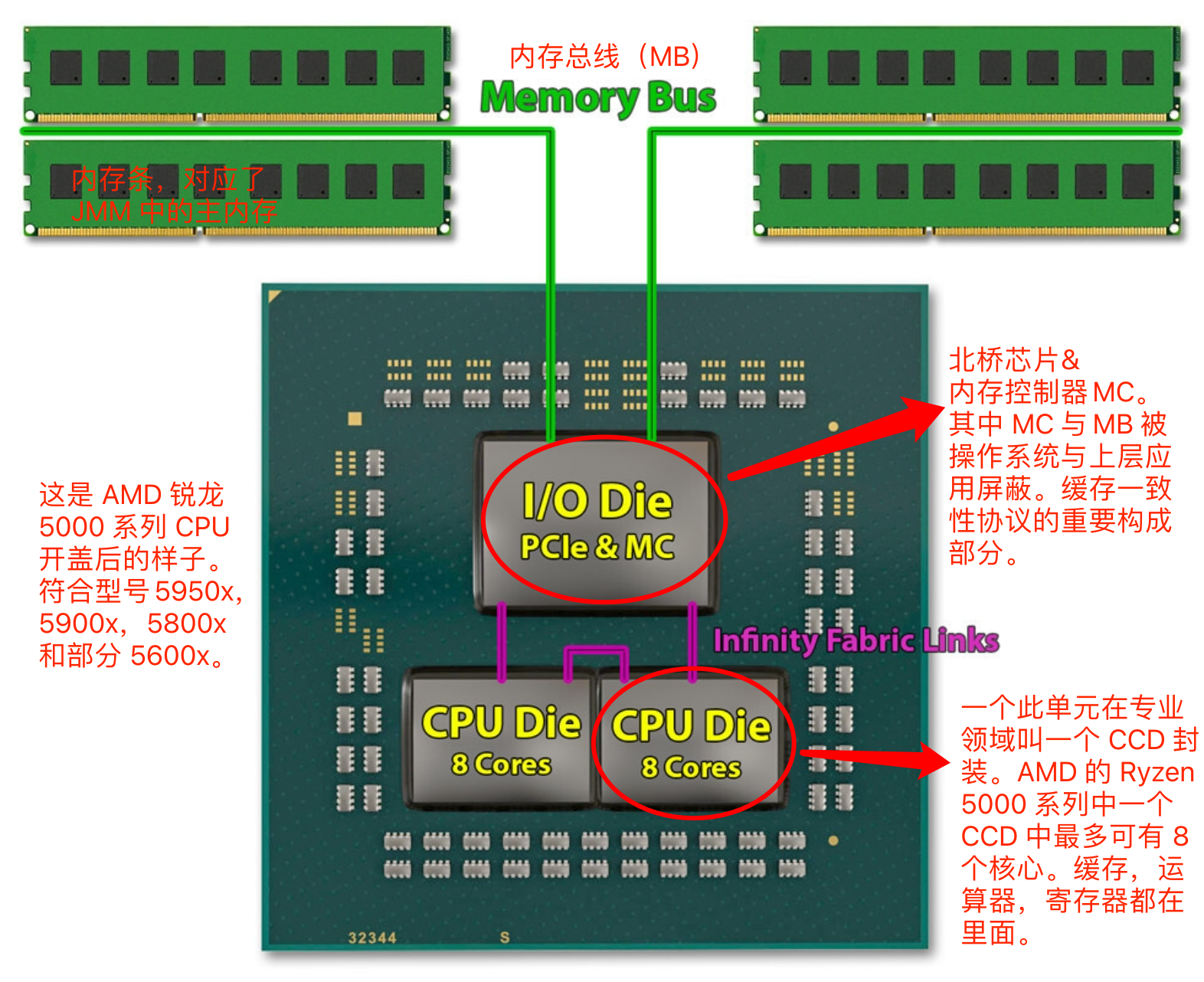
CPU 中的一个 CCD 封装:

缓存的架构:
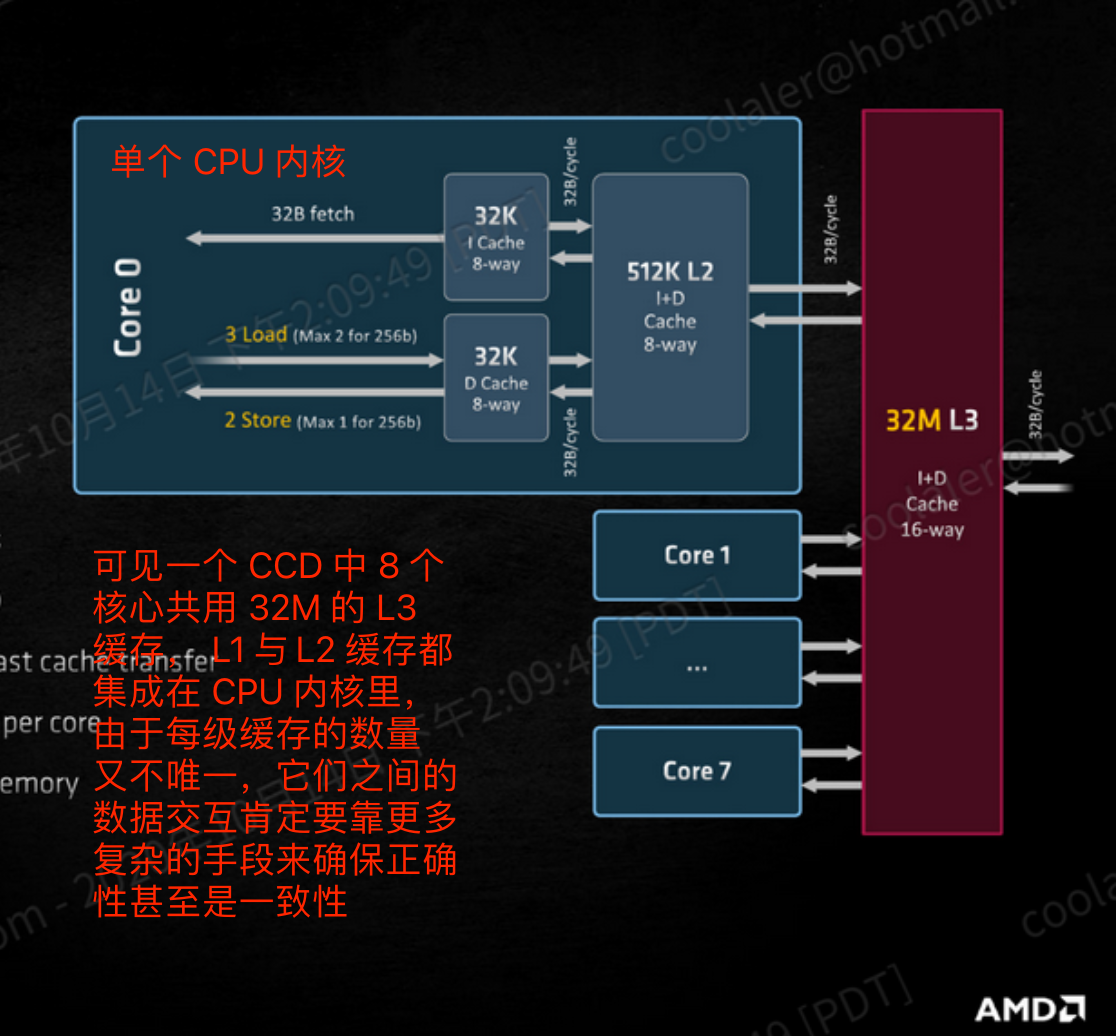
大致了解了 CPU 的架构后你会发现,上层应用屏蔽了多少复杂的东西啊!
结合上面说过的:
- JMM 主内存——内存条
- JMM 控制——数据调度策略(MC,MB,Cache Controller 等硬件与软件结合而实现)
- JMM 工作内存—— CPU 中的各级缓存(如核外 L3,核内的 L1,L2)
- JMM 中的线程—— CPU 内核里运算器在时钟周期内的任务执行过程
了解完硬件结构后是不是对软件有了更多的认识呢?
JMM 是一个蓝图,我们的 volatile 规则是这个蓝图里的一个条目,它就是基于这样的硬件条件,由 JVM 去实现的,很神奇吧!