简单明了编写《明日方舟》BGM下载工具
下载工具相关
工具链接(度云): ArknightsMusicDownloader.zip
工具链接(奏云): ArknightsMusicDownloader.zip
工具源码(gayhub): arknightsMusicDonwloader
音乐源: https://arknightsost.nbh.workers.dev/
起因
鹰角游戏音乐的水平可谓是业界顶尖了, 平时消遣听有时甚至会听到凌晨直接忘记睡觉- -
近日在B站找到由@我不识字呜呜呜 所整合的【明日方舟】游戏背景音乐合集, 非常喜欢
一看简介, 好家伙, 还做了下载地址, 这可太令人激动了, 毕竟开着b站听歌哪个机儿撑得住, 不过这一两百首BGM要一个个点击下载也着实蛋疼, 虽然作者也有打包, 不过也不能依赖作者费心思天天给你打包啊
本着消灭无意义重复劳动的想法, 简单地写个工具吧, 一键下载所有音乐, 可以同步作者的更新, 一次编写, 重复使用, 解放劳动力
步骤
-
确定语言
虽然我没咋写过 python, 不过爬虫果然还是得使用 python 做, 不然没内味, 就用 python3.10 吧
-
确定思路
查看音乐源, 初步确定逻辑结构, 就是简单的文件系统逻辑, 用个深度优先搜索或者广度优先搜索遍历下载就行了
-
分析网页
有了F12键, 人人都是抓包大师
谷某盘的后台数据直接返回 json 更是极大方便了编程工作, 不用花时间在解析 DOM 树上
-
主要代码
不得不说 python 的新手友好度是真的高, 简单查了一下语法和工具库, 可写得主要代码如下
# 深度优先下载文件 # 1:如果 obj 是文件链接直接下载返回 # 2:如果 obj 是文件夹,则请求链接,拿到文件夹内的内容(obj list),迭代 dfs(obj) def dfs(parent, obj): name = obj['name'] path = folder + parent + name if parent != '' and os.path.exists(path): if 'size' in obj and fully_downloaded(path, int(obj['size'])): return file_url = domain + parent + urllib.parse.quote(name) dir_url = file_url + '/' if 'size' in obj: size = int(obj['size']) offset = resume_offset(path, size) if offset != 0: headers['Range'] = 'bytes=' + str(offset) + '-' downloads(path, file_url, size, offset) else: mkdir(path) try: data = getfiles(dir_url) for sub in iter(data): dfs(parent + name + '/', sub) except ProxyError: print('Network Error (PROXY) for url: ' + dir_url) except SSLError: print('Network Error (SSL) for url: ' + dir_url)# 写入文件 def write_to_file(filename, level, response, size, offset): # 进度条显示 pbar = tqdm(total=size, initial=offset, unit='b', unit_scale=True, desc=filename) with open(filename, level) as f: for chunk in response.iter_content(chunk_size=1024): if chunk: offset += len(chunk) f.write(chunk) f.flush() pbar.update(len(chunk)) pbar.refresh() pbar.close()# 下载内容 def downloads(filename, url, size, offset): response = requests.post(url, headers) if response.status_code == 206: # 服务器支持断点续传 write_to_file(filename, 'a', response, size, offset) elif response.status_code == 200: # 服务器不支持断点续传 write_to_file(filename, 'wb', response, size, offset) else: # 下载失败 print('statusCode[' + str(response.status_code) + '] for [' + filename + ']\n')
结果
IDE下运行:
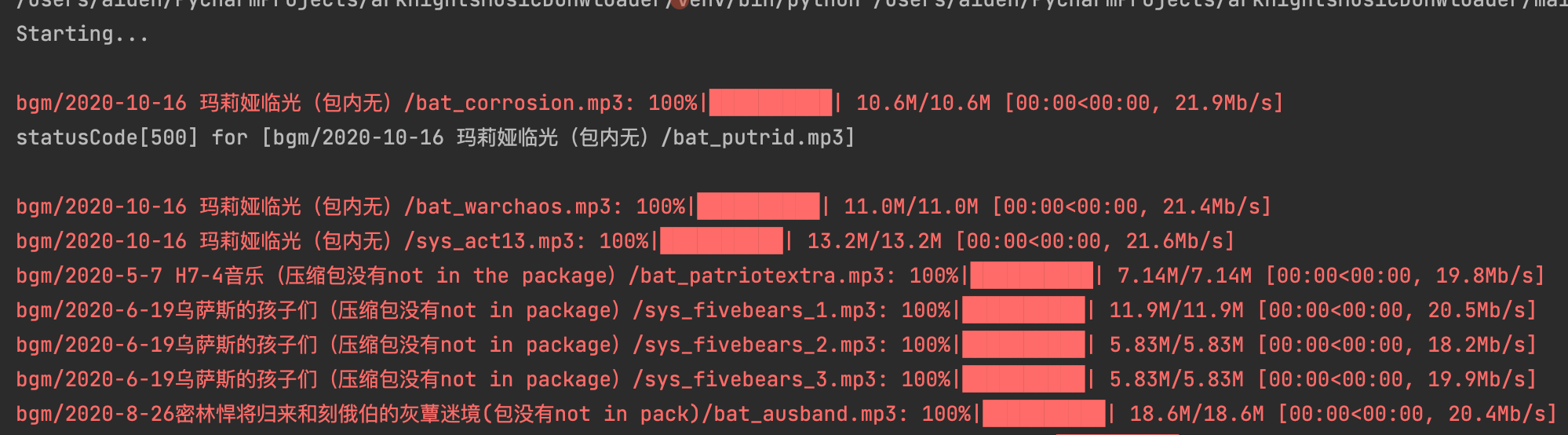
打包后在 Windows 下运行
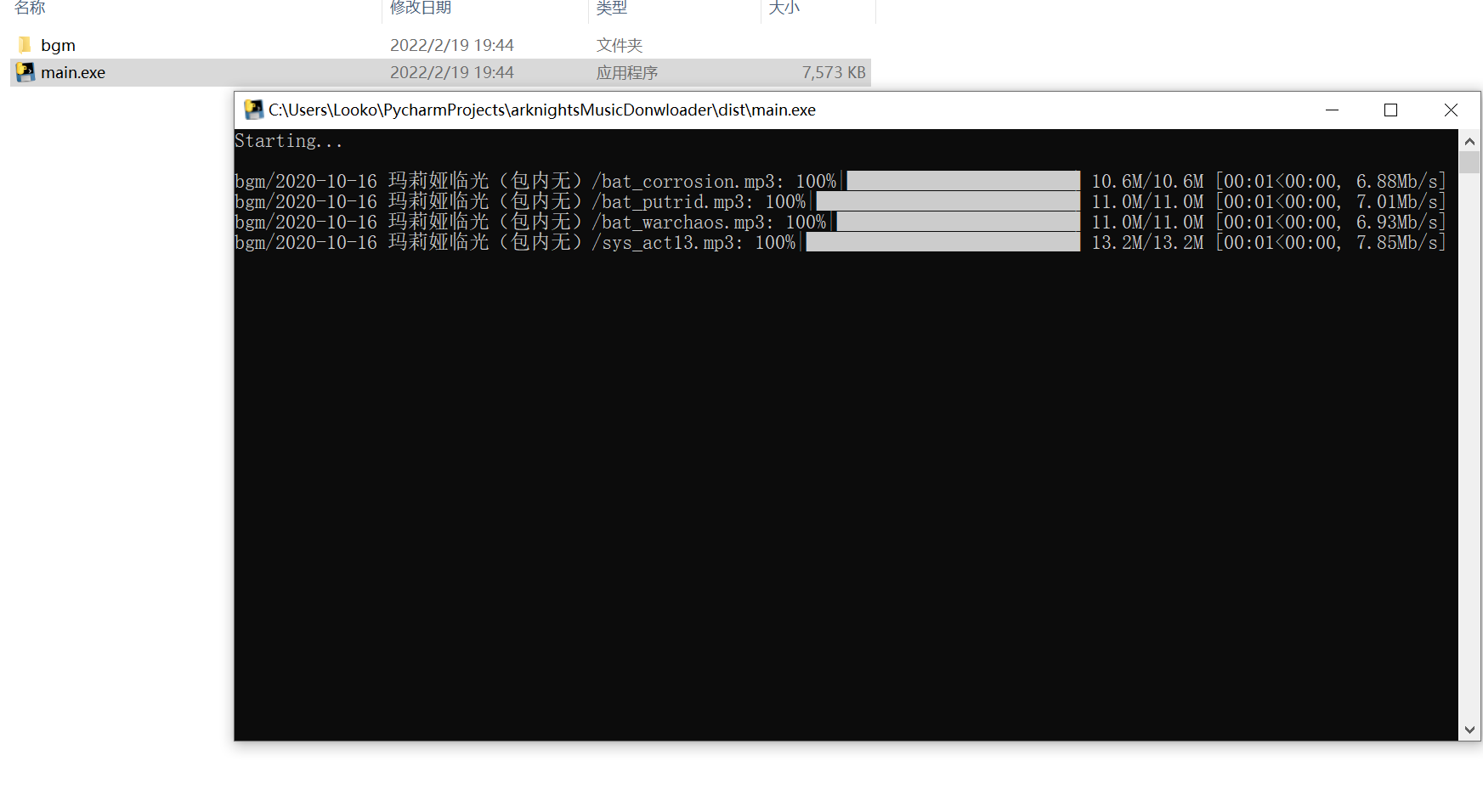
简单明了,十分舒服
评论
其他文章